There are a lot of discussions about how to futureproof science applications in HPC. And a discussion on Twitter prompted me to write this essay.
The Problem with HPC Kids Today
First, let us clearly define the problem:
- New hardware come and go
- Applications outlive hardware
- Programming models can’t keep up
You’ll have to pardon the doodles but I felt like drawing this week.
Below is the lifetime of a typical HPC app on a time axis. Sorta. This is probably a community application, developed by several people, sometimes written in mixed languages, with several forked versions, all doing their best to squeeze out performance of the system they are currently using to accomplish their science.

Sometimes a developer doesn’t want to depend on someone else’s library. So they’ll go rogue, build their own libraries, often to the detriment of performance (don’t do it, I beg thee). As my colleague and friend Michael Wolfe (PGI) used to say “PhDs have been written just to squeeze performance out of this particular algorithm.” And when those algorithms didn’t exist he would say the corollary “PhDs are waiting to be written on this topic.”
If Type A apps are full of dependencies, the other extreme is Type C apps with zero dependencies. Somewhere in the middle is Type B apps. More on this in a bit.
So Type A app, say a large community supported application, with 20+ years of development history and scars along the way, is probably filled with design choices no one really knows why it’s that way. “Legacy” they’ll say. Probably that choice was based on the system the original developer had access to.
The GPU Hackathon Series events I created uncovered many of these. Once was a 17yo application for particle track tracing used a Brookhaven National Lab. First two days a group of five domain science developers who were not the original developers, tried to make sense of the data structures. Whenever they pulled one pointer or rearranged a struct to better fit the memory layout, it would break. Finally at the end of day 2 (of 5) I asked
“do you understand the physics enough to write your own app?”
“of course” they said confidently, they are particle physicists after all
“then why not start from scratch?”
A day later they had a much shorter (LoC), efficient, and infinetly faster application, done, written in C++ using Kokkos. Their vision for what could be done was limited on what had been done. Even brilliant scientists, it seems, are vulnerable to a psychological heuristic known as anchoring. It was so prevalent that I began to read books on psychology and group dynamics. I became a master manipulator (for good), able to redirect even the most stubborn of “but that’s not how it *should* work” people.
I came across many such examples during my tenure as training lead at ORNL. The CFD application that had an absurd number of nested loops with peculiar loop bounds. Probably some legacy L2 caching optimization that sat there, undocumented. The master c++ developer, that spent a whole day walking through debugger output, declaring all compilers he tried trash since it couldn’t figure out how to optimize that important, yet slow, kernel he had written. With each of these personas, I would first attempt logic, then negotiate, finally manipulate (for good) to get them unstuck from that sort of unproductive loop thinking.
The HPC community as whole carries a burdensome anchor. What started as a field of hero developers able to create and port an application on just about any system they had access to, has morphed to large community applications with a number of developers, strugling to keep up with hardware changes and requiring additional human effort to help. (See DOE early science programs such as NESAP, CAAR, and ESP)
“Friendly users” and not “user friendly”
While I was too young to have been there in the early days of HPC, through the magic of the time machine that is Google, we can get a glimpse of what it looked like back-in-da-day…

The article, by Michael Hannah of Sandia National Labs, describes how Cray was starting to get pressure to compete with new commodity hardware called a PeeCees (ok fine, IBM PC). Here are more excerpts
“As new generations of supercomputers supplant the existing machines, they’ll require completely new software to run them. I expect this trend for speed at the expense of user interface to continue… There’s a great need for the large and the small, but the in-between computer is neglected.” — Michael Hannah, SNL
Preach brother Michael, preach.
But here is the example of the anchor I mentioned earlier:
“To take advantage of the Cray-1’s speed scientists must modify their thought processes and program code to conform to its hardware architecture. In contrast, the PC’s advantage is that its interfaces are easily modified to conform to the needs of both users and other computers”
Did you catch that? In the very early days of HPC, way back when we were all young an innocent (and I was like, 7yo) the psychology that would anchor the future of HPC was laid out: if you want to use the big rigs, you gotta pay the price and do most of it yourself. It’s the price of innovation. That may have been true in the early days of one-off systems, but today’s systems are largely built using commodity hardware, why should users bear the early brunt of making things work?
As a hobby I enjoy reading about the olden days of supercomputing, especially when I’m travelling. In the many articles I’ve read the story is pretty much the same and Michael is not the first nor the last to point this expectation out. Add every workshop I’ve ever been to and the question is “who will build the tools?” and “whose responsibility is it to maintain xyz?”
Mythical Creatures of HPC
If everything is up to the user of the HPC system they will need a very broad set of skills to make their applications work. We know them as Hero Programmers and in the early days it was necessary to be skilled at everything because computing was the primary limiting factor, so there was only so much one could really compute.

It was both simpler and more complicated back then. Equations were truncated approximations, the number of particles limited to merely megabytes of memory. The science was limited by what one could do on a computer and the difficult work was how to creatively squeeze out more science (read math) than the system could do if coded naively.
Today’s systems are another matter, with processors, co-processors, specialty cores, multiple memory levels/sizes/bandwidths/latencies, intrinsics, and communication between CPUs, GPUs, I/O, even fabric based offload collectives. Today’s applications are multi-physics, multi-modality, multi-modular, multi-language, multi-system, multi-developer…
Oof.
With the help of my daughters I developed a new set of HPC personas for today’s modern HPC professional.
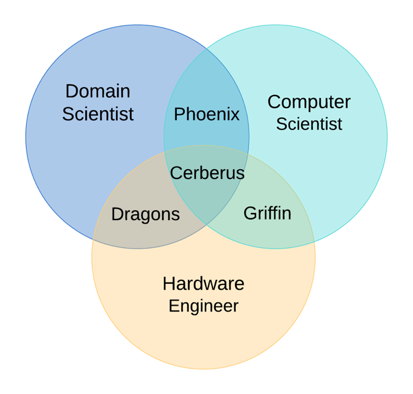
The hero programmer is now known as The Cerberus. They are gatekeepers of HPC, and have high expectations that you should exhibit all three types of expertise that they claim they possess, or else “you don’t belong here.” Fortunately these are rare.
The most common is the Phoenix, aka computational scientist, living somewhere between domain and computer sciences.
Griffins are powerful majestic creatures, able to squeeze performance out of any hardware. The library eggs they build for us are pure gold.
Then there are Dragons. These are rare, but responsible for generating deluge of datasets. They can be found in projects such as SKA, LIGO, CERN. (Pardon my Physicist bias, let me know where else you’ve seen HPC Dragons flying).
Unlike workshops, the GPU Hackathons allowed me to play with partnering these different personas with developer teams of large applications. What I observed was that combining computer scientists, with enough knowledge of the underlying hardware, together with domain scientists, with enough knowledge of the tools being used to access performance, worked best. These teams were productive, collaborative and yielded the best results especially when, individually, not a single person on the team was a cerberus.
New Lines Drawn
“This is fun and weird and all, but what about Type B applications you mentioned above?”
Glad you asked. Type B apps are what all HPC apps aspire to be. They are big (LoC), performant, feature rich, have a large user community of users, and can run on just about any system. Type B apps cannot wait, because they have a large number of users that rely on them. If the institution users depend on for compute buys new hardware, the app needs to run, well, and keep science moving. Therefore Type B apps cannot cater to every architecture, they will never have enough developers to tweak kernels, and they can’t wait on community based libraries to be developed if they want to stay at the bleeding edge of technology.
My opinion based on my experience (don’t @ me), is that for Type B apps to thrive they’ll need to delineate duties within a perf x feature ownership/leadership graph shown below (PeFOwL? help).
On the community side, domain scientists keep the responsibility of app maintenance and feature development, while computer scientists own major aspects of data movement, the greatest bottleneck affecting HPC today.
On the vendor side, domain scientists they hire are responsible to develop libraries of fundamental algorithms used in their respective domains, while computer scientist they hire are responsible to develop performant math+other libraries for their hardware.

If I had a wand, every vendor would claim ownership of the layer of performance libraries for every piece of hardware they make available. I would even concede that their libraries could remain closed source IF they agree with the communities they serve on a similar interface and make sure it’s extra performant where possible.
All of this is a long winded way to say: we need to renegotiate with vendors where our responsibility ends and their’s begins, and we must raise the anchor dropped in the early calm days of HPC if we are to chart a new course in this stormy sea of very sophisticated heterogeneous hardware we find ourselves in.
(Thank you for indulging me on the Harry Potter + sailing references)

Leave a comment