Following my 15th GTC, I review the week and share a couple of items I found interesting at GTC24.
Let’s recap some highlights over the years:
– In 2009, I watched with excitement as Jensen announced the GT300
– That same year, Leonardo 2.0 painted the Mona Lisa
– In 2013 I presented at GTC about the OLCF’s Titan supercomputer
– In 2017 I presented at GTC about OLCF’s upcoming Summit supercomputer
– In 2024 I attended as an employee of a startup building tools that run on GPUs!

Baby Fernanda meets Jensen’s leather jacket for the first time.
I could not have imagined then that I would one day end up working for the company I admired so much, let alone that I would build two of the world’s fastest supercomputers with NVIDIA’s hardware. 2009-era Fernanda would have laughed at the thought.
Fast-forward to 2024, and I was as excited to attend as 2009. Perhaps more so, after a 3 year in-person hiatus, this year I attended as a proud employee of a GPU-based software startup!
So here are my top observations.
Overall impression of the event
One of the reasons GTC has been my favorite conference is that if you peeked into any room, you’d see code up on the screens. In the early days of CUDA, attendees were developers presenting their algorithms and implementations. The audience, also developers, would happily share their ideas, and what they had tried. NVIDIA devtechs would share a ton of very technical content. It’s not that this type of content wasn’t present, it’s just that it wasn’t as prevalent and I missed that kind of interaction. This year, the presentations from NVIDIA were largely about marketing their tools. To be fair, NVIDIA announced a lot of tools and there was only so much time. But things must evolve and GTC has certainly evolved since the early scrappy GPU developer community days.
Unlike AI, the early days of CUDA were more on the academic side without the clear external pressure to monetize. I don’t expect to see a return of those early GTC years, because if someone built something neat with AI, they will likely present as a startup, not as a developer. Regardless, there was still excitement in the air, and new toys to play with.
Here are a few talks I enjoyed:
Mixed emotions about mixed precision
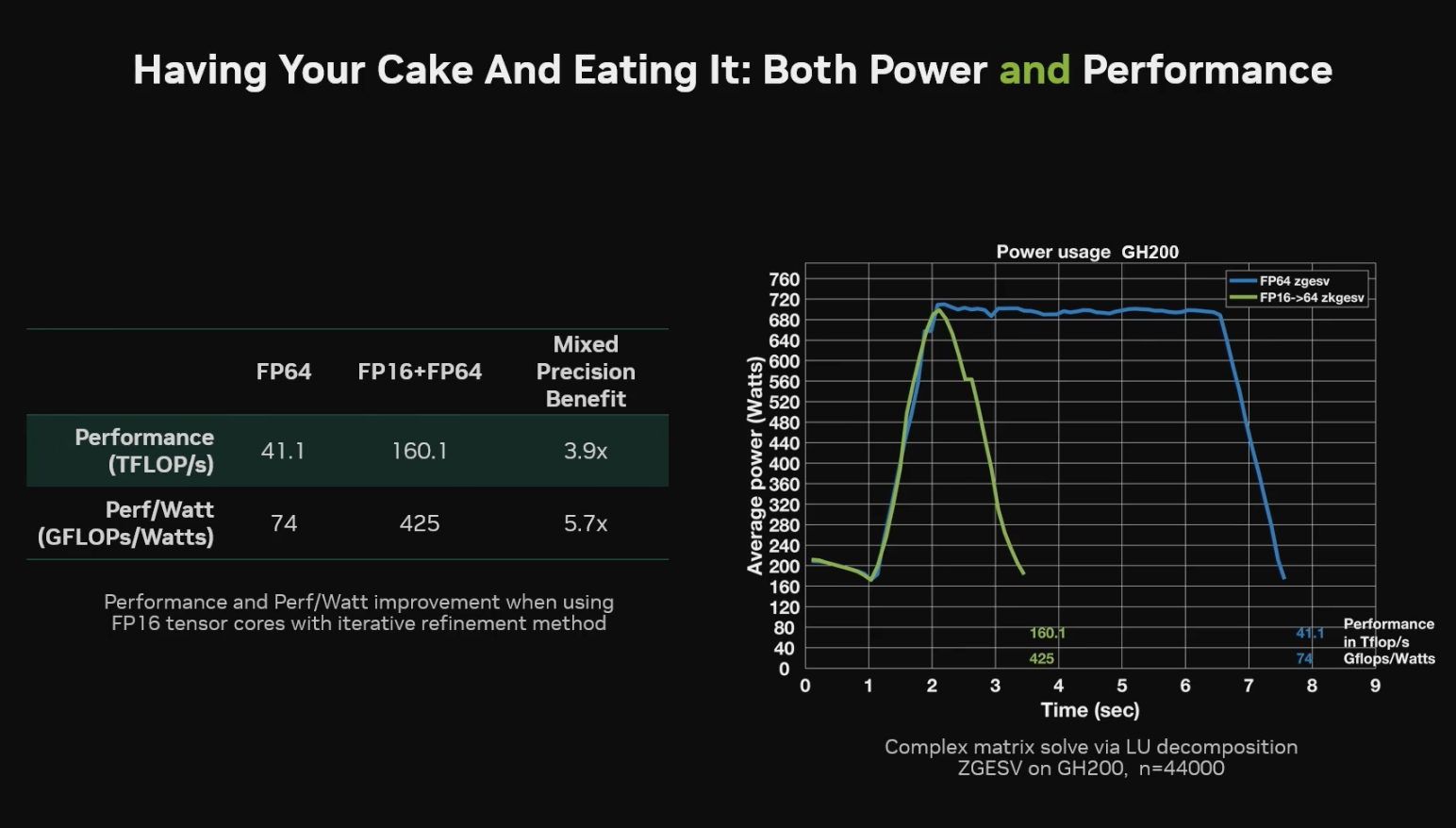
If you want to infuriate an old “greyHPCer”, suggest to them that FP64 is not always necessary and that their work can be partly accomplished with lower precision. NVIDIA’s DevTechs have done some fantastic work to show this is indeed the case. Stephen Jones’ talk on the future of CUDA was fantastic. He starts out reminding us that native FP64 precision = energy costs, because floating point arithmetic scales N^2 of the size of the mantissa. But you can use a fraction of the power using tensor cores and still get equivalent precision using mixed precision. He proved that if you can use FP16 TCMMA instead of FP64 FMA you can gain a factor of 20x in power efficiency.

While there is a lot of grumbling about the ever decreasing real estate of FP64 on the latest GPUs, the reality is that mixed precision is amazing and every HPC application developer should test and adopt mixed precision. NVIDIA developers have already provided performant libraries (cuBLASDx and cuBLASLt to name a few) that can help with that transition. Will it work for all HPC problems? No. But it seems likely that most HPC applications could benefit from adopting some level of mixed precision.
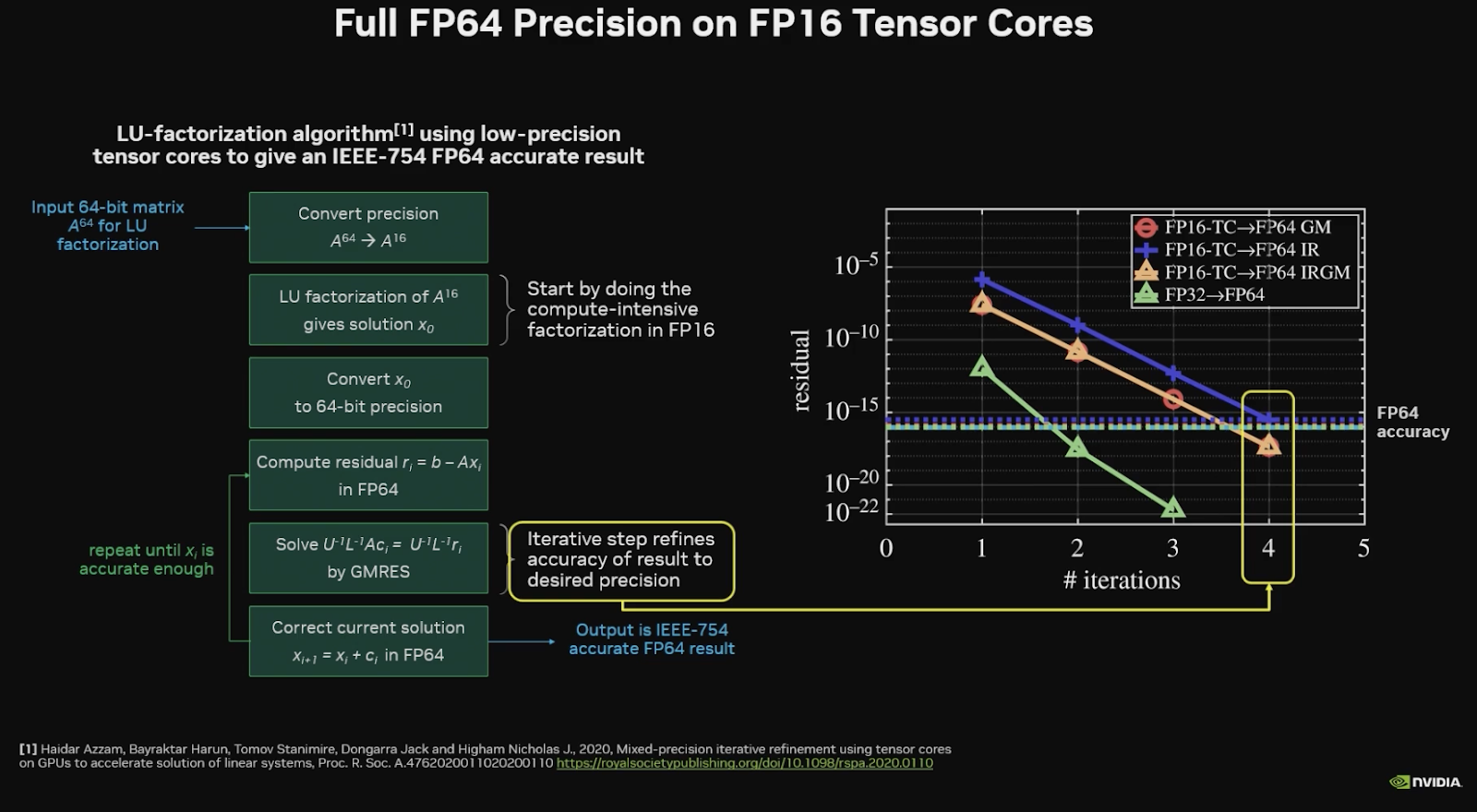
And here’s the slide where they show reduced energy use.
Composability and Productivity with Legate
Before I talk about Legate, I want to say that the number of NVIDIA libraries have exploded and are getting difficult to keep track of. Many of the underlying numerical libraries are packaged under multiple frameworks, and framework names often don’t describe their function. It may be time for NVIDIA to step back for a bit and put together a comprehensive product map.
For example, it seems like the Legate/Legion path is non-existent on NVIDIA’s HPC webpage, yet it’s promoted as an HPC programming model. It’s part of the nvHPC ecosystem yet I couldn’t even navigate to anything Legate-related from the main HPC page, and it took far too long to figure out what it is and what it isn’t. In short, I think Legate is a NumPy replacement with an Apache Arrow data structure PGAS-like model with cuNumeric as a compute interface (instead of like, BLAS). (This is after going all over the place on the website.)
Anyway, what I love about Legate is its composability. If you’re new to this buzzword, you can think of composability as separating all workload into three main layers: interface, compute, and locality. In simpler terms, it’s: how I express what I want, a runtime that configures what’s needed, and the hardware environment it’ll run on.
If you think composability sounds a lot like DSL -> jit compiler -> optimized binary -> hardware, you have the right idea, but it’s even more generalized than that. Your interface could be some scientific application, ML, or just some post-processing. From there, an intermediate representation is generated and shipped to some runtime. That runtime could focus on scaling, or focus on running on accelerated hardware, or both. The runtime might be smart enough to understand data locality, and ship work next to the data, or the runtime may be smart enough to ship work to the most appropriate hardware based on some criteria.
Legate seems to imply you can go from local laptop to supercomputer without much effort. Legate also seems to imply it’s targeting productivity and scaling, not necessarily performance. Some might wonder why they might bother running on a GPU or supercomputer if not aiming for performance? The answer is capability. There’s probably more than enough performance to beat CPU-only performance and there’s a ton of “performance” you can reclaim from enabling productivity alone.

So much tech, so little time… The conference was over just when it was getting good. There was so much more announced at GTC which I’ve yet to really dive into, like FP4/FP6 and new algorithms using them. Another tool I learned about was NVIDIAs AI Workbench which I’ve installed and have started exploring. I might write something about my experience with this tool at a later time.
The future of HPC at GTC
In terms of HPC, GTC was more of a reunion even though many GPU developers chose to attend virtually. Some of my friends were discouraged by the levels of AI hype, and had concerns the event was going to be overwhelmingly AI-focused (they weren’t wrong). Another friend who attended in person suggested GTC be split into scientific computing and AI. Separating HPC GPU developers from AI practitioners would probably bring back some of the value for these folks that chose to attend virtually.
From where I sit in my career, smack in the middle of AI, data science and HPC, having AI and scientific computing collocated is still valuable for me, but I would like to see more academic talks next year. There was a ton of opportunity to have more technical talks on mixed precision, DPUs, the ever growing HPC python ecosystem… For example, major HPC center talks were largely about what the center does. There was too little focus on specific scientific outcomes and what they are accomplishing with the latest nvGPUs. NVIDIA is still pushing novel hardware and software, but the HPC content from major centers didn’t reflect that. By not hosting these academic talks at GTC, NVIDIA risks fragmenting the community into their respective domain specific conferences and we will lose GTC as an event where we can share common methods.
I do expect that next year will be more interesting in terms of AI outcomes. I don’t see AI winter coming just yet. The pace of AI methods has not slowed down and with everything being so new, I think most companies will still be barely scratching the surface of what is possible come next GTC. HPC is also ramping up their own AI-for-science efforts like digital twins, <domain>-informed AI, and explainable AI. Separating scientific computing from AI communities would be a mistake. AI benefits from the scientific rigor that computational scientists bring to the table and we will need the new methods they develop to help bring trust and fidelity to AI. I’m looking forward to seeing what people build over this coming year.

Leave a comment